����l(f��)�F(xi��n)Խ��Խ��ľW(w��ng)վϲ�gʹ���Ԅ���ȡ�˺��ڣ���С����ȥ�����°ٿƾW(w��ng)վ����һ�����؈D���£�
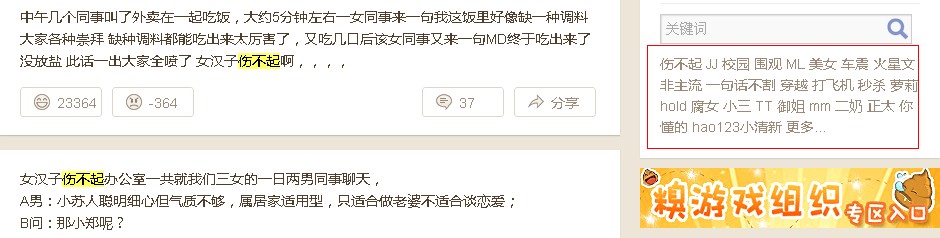
���ψD����ҿ���߅���֣��������·�����һ���Ԅ���ȡ�Ę˺��ڡ�ͨ�^�c���@Щ���F(xi��n)�l�ʱ��^�ߵ��P�I�~���Ñ����Կ������г��F(xi��n)�^���P�I�~�����ӡ��Y��վ����������f�����ɞ�һ��������������ߡ����ھW(w��ng)վ���ݶ࣬���¿죬������͵ľW(w��ng)վ���f���DZ���������������������ߣ�Ҳ���ɞ�W(w��ng)��OӋ�ij���څ��֮һ��
�mȻ�W(w��ng)��OӋԽ��Խ��ݣ������@�����OӋ����������Ŭ���s���D���ġ��҂������°ٿ�һ�����ƺܺ��εľW(w��ng)վ���������Ո���I(y��)�ľW(w��ng)վ���O��˾��������Ԓ���ɱ���Ͷ�Ҫ�Î��f���@Ҳ�ܽ�ጞ�ʲô�҂������������۵��S�ֵ�һ�����ߣ��f�����������˴������OӋ���L�r�g��Ŭ���Y����
�@���Ԅ���ȡ�˺����OӋҲ��һ�ӡ�С���о���һ�Εr�g�������˺ܶ��Y�ϣ��ŵó����^����һ�c���O�÷��������H���@���������nj����еij�����Ч����ֻ�nj�JAVA������Եġ��ڴˌ��˶γ����N�ρ��c��ҷ�����
- import java.io.BufferedReader;
- import java.io.InputStreamReader;
- import java.net.URL;
- import java.util.regex.Matcher;
- import java.util.regex.Pattern;
- public class URLTest {
- /**
- * @param args
- * @throws URISyntaxException
- */
- public static void main(String[] args) throws Exception {
- URL url = new URL("http://www.ascii-code.com/");
- InputStreamReader reader = new InputStreamReader(url.openStream());
- BufferedReader br = new BufferedReader(reader);
- String s = null;
- while((s=br.readLine())!=null){
- s = GetLabel(s);
- if(s!=null){
- System.out.println(s);
- }
- }
- br.close();
- reader.close();
- }
- public static String GetContent(String html) {
- //String html = "
- 1.hehe
- 2.hi
- 3.hei
- String ss = ">[^<]+<";
- String temp = null;
- Pattern pa = Pattern.compile(ss);
- Matcher ma = null;
- ma = pa.matcher(html);
- String result = null;
- while(ma.find()){
- temp = ma.group();
- if(temp!=null){
- if(temp.startsWith(">")){
- temp = temp.substring(1);
- }
- if(temp.endsWith("<")){
- temp = temp.substring(0, temp.length()-1);
- }
- if(!temp.equalsIgnoreCase("")){
- if(result==null){
- result = temp;
- }
- else{
- result+="____"+temp;
- }
- }
- }
- }
- return result;
- }
- public static String GetLabel(String html) {
- //String html = "
- 1.hehe
- 2.hi
- 3.hei
- String ss = "<[^>]+>";
- String temp = null;
- Pattern pa = Pattern.compile(ss);
- Matcher ma = null;
- ma = pa.matcher(html);
- String result = null;
- while(ma.find()){
- temp = ma.group();
- if(temp!=null){
- if(temp.startsWith(">")){
- temp = temp.substring(1);
- }
- if(temp.endsWith("<")){
- temp = temp.substring(0, temp.length()-1);
- }
- if(!temp.equalsIgnoreCase("")){
- if(result==null){
- result = temp;
- }
- else{
- result+="____"+temp;
- }
- }
- }
- }
- return result;
- }
- }
���У�GetContent�Á��@ȡ�˺����ݣ���GetLabel�t���ګ@ȡ�˺���
���H�ϣ��@�����t���t�\���е�һ�N��С�����\�õ����@�����t���t�ı��_ʽ�ǣ�
<[^>]+>���@�����t���_ʽ����ƥ������html�˺�,����100%ƥ�䣬����Ҫע����澎�a��ʽ���xȡ�ľ��a��ʽ������һ�����_ʽ��>[^<]+<���@������ƥ��˺����ݡ�������С���������t���t���Ƿdz��ľ�ͨ�����ҕr�g���ޣ�ֻ�о������@һ�N�����������O�þW(w��ng)��Ԅ���ȡ�˺���߀��htmlparse��sax��dom4j�ȣ��������Ă������ã��Ă����F(xi��n)���������ף���Ҫ����Լ�ȥ̽���ˡ�